



















探索Ollama在A5000 GPU服务器上的表现:全面的基准测试
随着AI领域的发展,对高性能硬件的需求持续增长,以部署和托管像DeepSeek-R1、Llama2等大型语言模型(LLM)。本文将探讨Ollama在搭载NVIDIA Quadro RTX A5000的服务器上的性能,分析基准测试结果,并评估此配置托管LLM的适用性。
服务器规格
基准测试是在以下硬件和软件设置上进行的:
服务器配置:
- CPU:双 12 核 E5-2697v2(24 核,48 线程)
- 内存:128GB RAM
- 存储:240GB SSD + 2TB SSD
- 操作系统:Windows 11 Pro
- 网络:100Mbps~1Gbps带宽
- 软件:Ollama 版本 0.5.7
GPU详细信息:
- GPU:Nvidia Quadro RTX A5000
- 计算能力:8.6
- 微架构:Ampere
- CUDA 核心数:8192
- 张量核心:256
- GPU内存:24GB GDDR6
- FP32 性能:27.8 TFLOPS
这种强大的配置将 A5000 定位为 AI 应用程序的顶级 GPU 服务器,平衡了性能、内存和与现代 LLM 框架的兼容性。
A5000上LLM的基准测试结果
下表总结了多个模型在Ollama上运行时的基准性能:
| 模型 | deepseek-r1 | deepseek-r1 | llama2 | qwen | qwen2.5 | qwen2.5 | gemma2 | mistral-small | qwq | llava |
|---|---|---|---|---|---|---|---|---|---|---|
| 参数 | 14b | 32b | 13b | 32b | 14b | 32b | 27b | 22b | 32b | 34b |
| 尺寸 | 7.4GB | 4.9GB | 8.2GB | 18GB | 9GB | 20GB | 9.1GB | 13GB | 20GB | 19GB |
| 量化 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| 运行平台 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 |
| 模型下载速度(mb/s) | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 |
| CPU 利用率 | 3% | 3% | 3% | 3% | 3% | 3% | 3% | 3% | 3% | 3% |
| RAM 利用率 | 6% | 6% | 6% | 6% | 6% | 6% | 6% | 5% | 6% | 6% |
| GPU vRAM | 43% | 90% | 60% | 72% | 36% | 90% | 80% | 50% | 80% | 78% |
| GPU 利用率 | 95% | 97% | 97% | 96% | 94% | 92% | 93% | 97% | 97% | 96% |
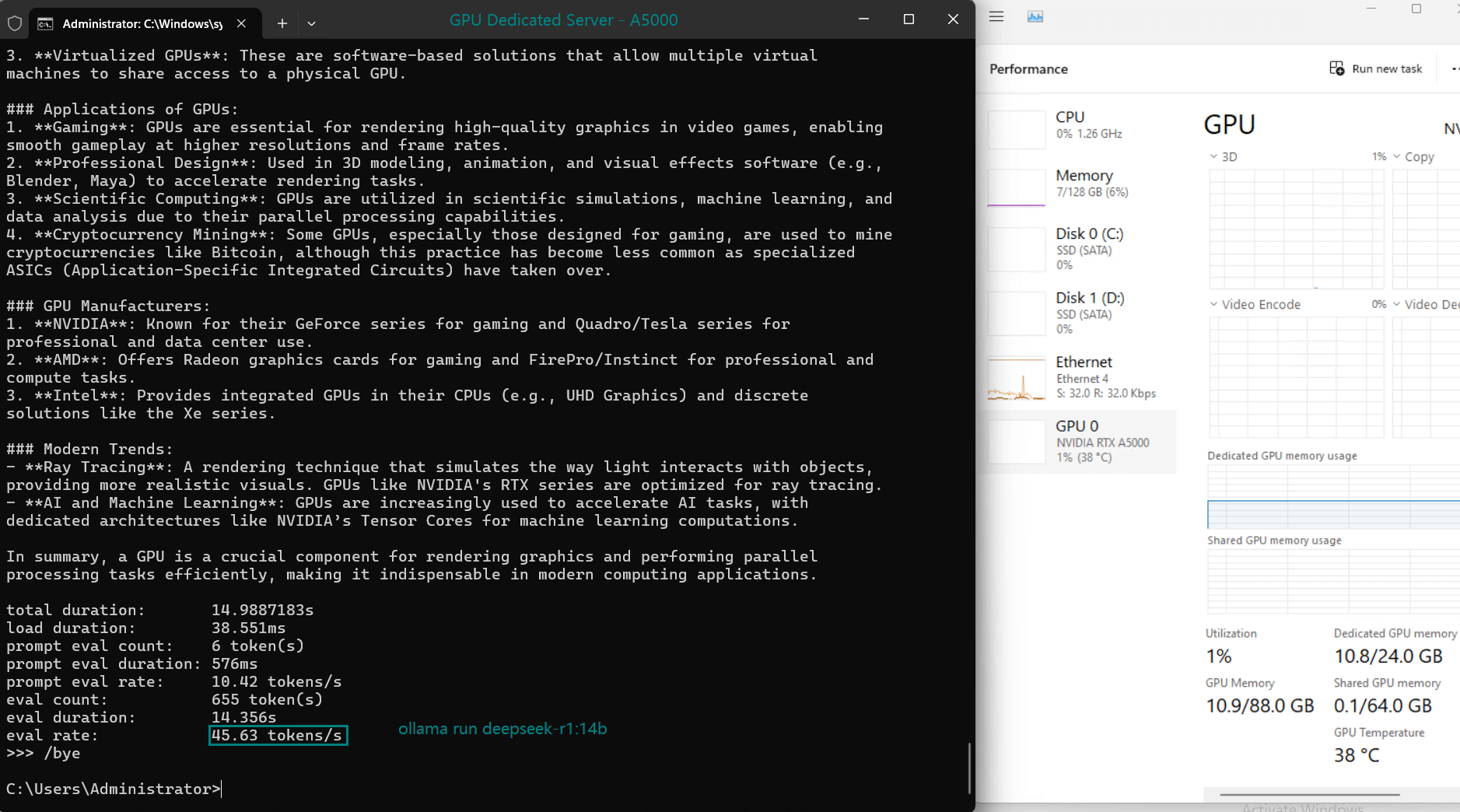
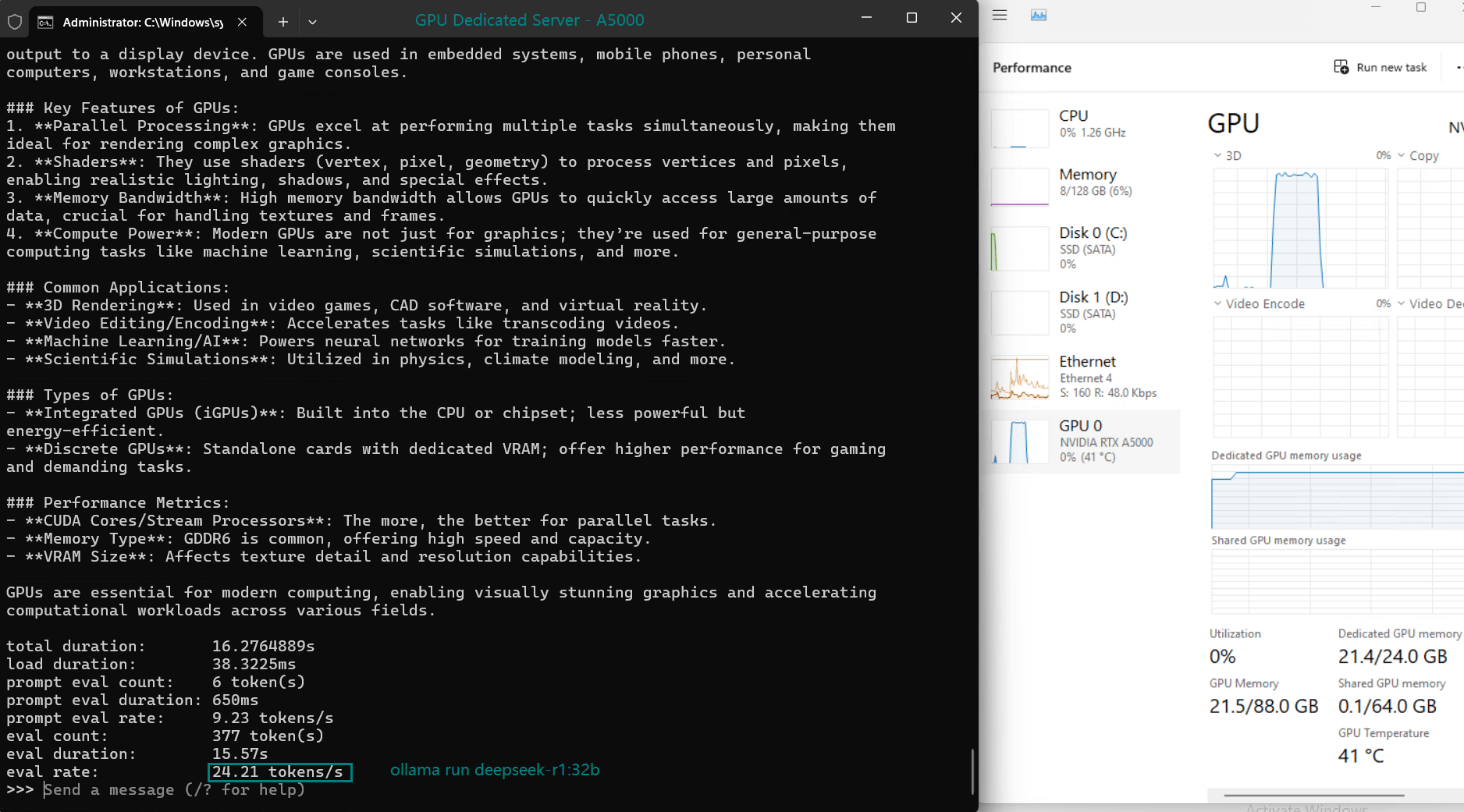
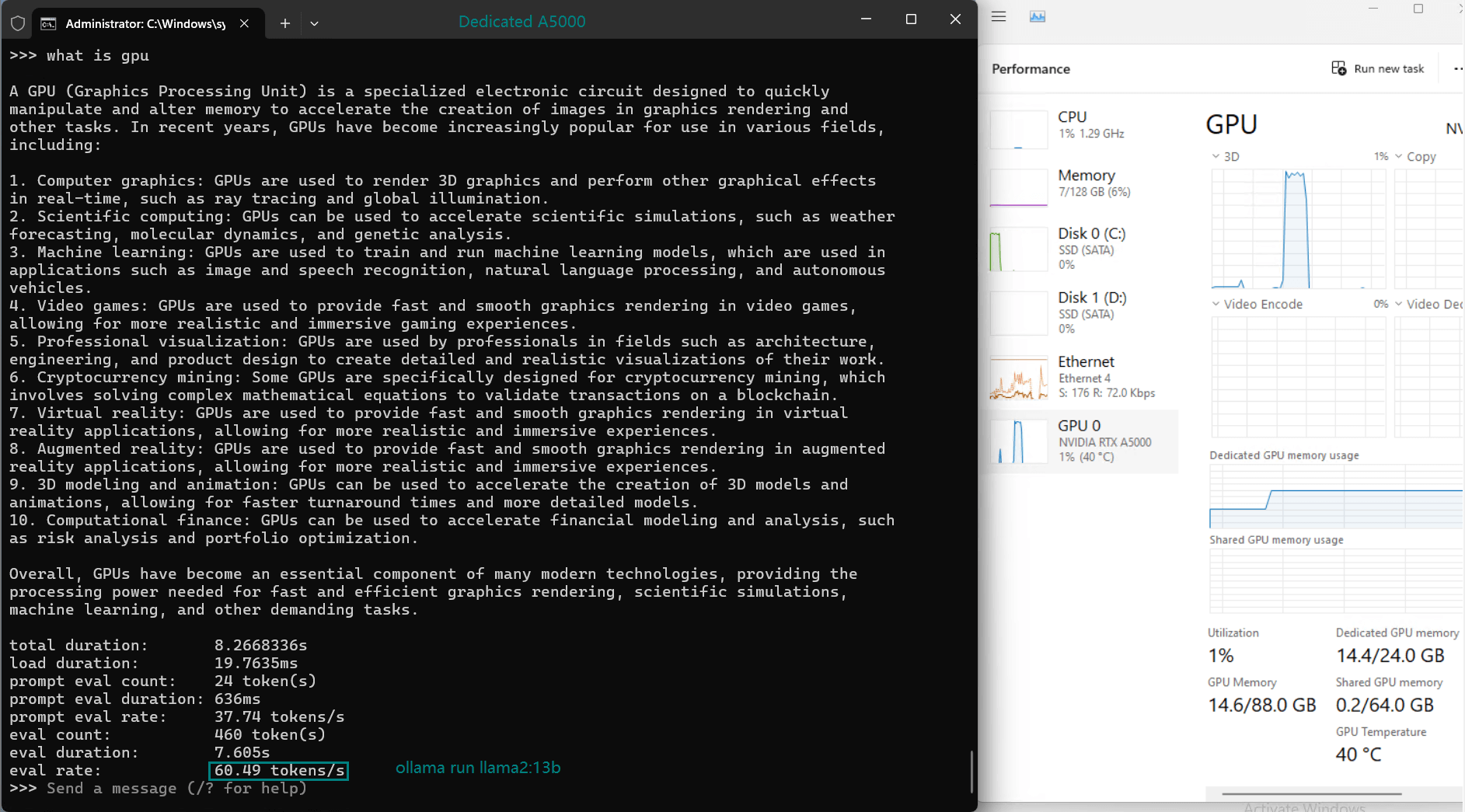
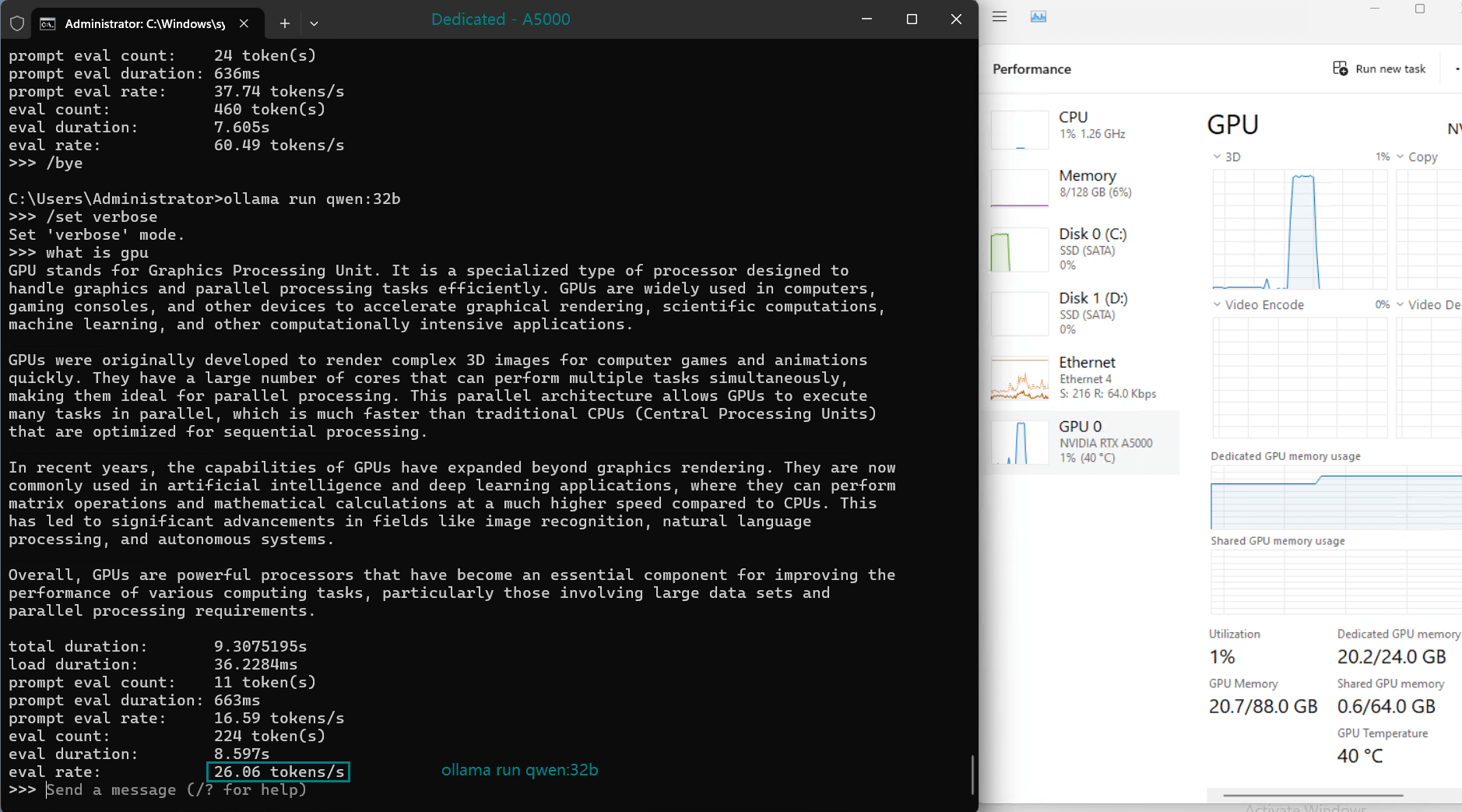
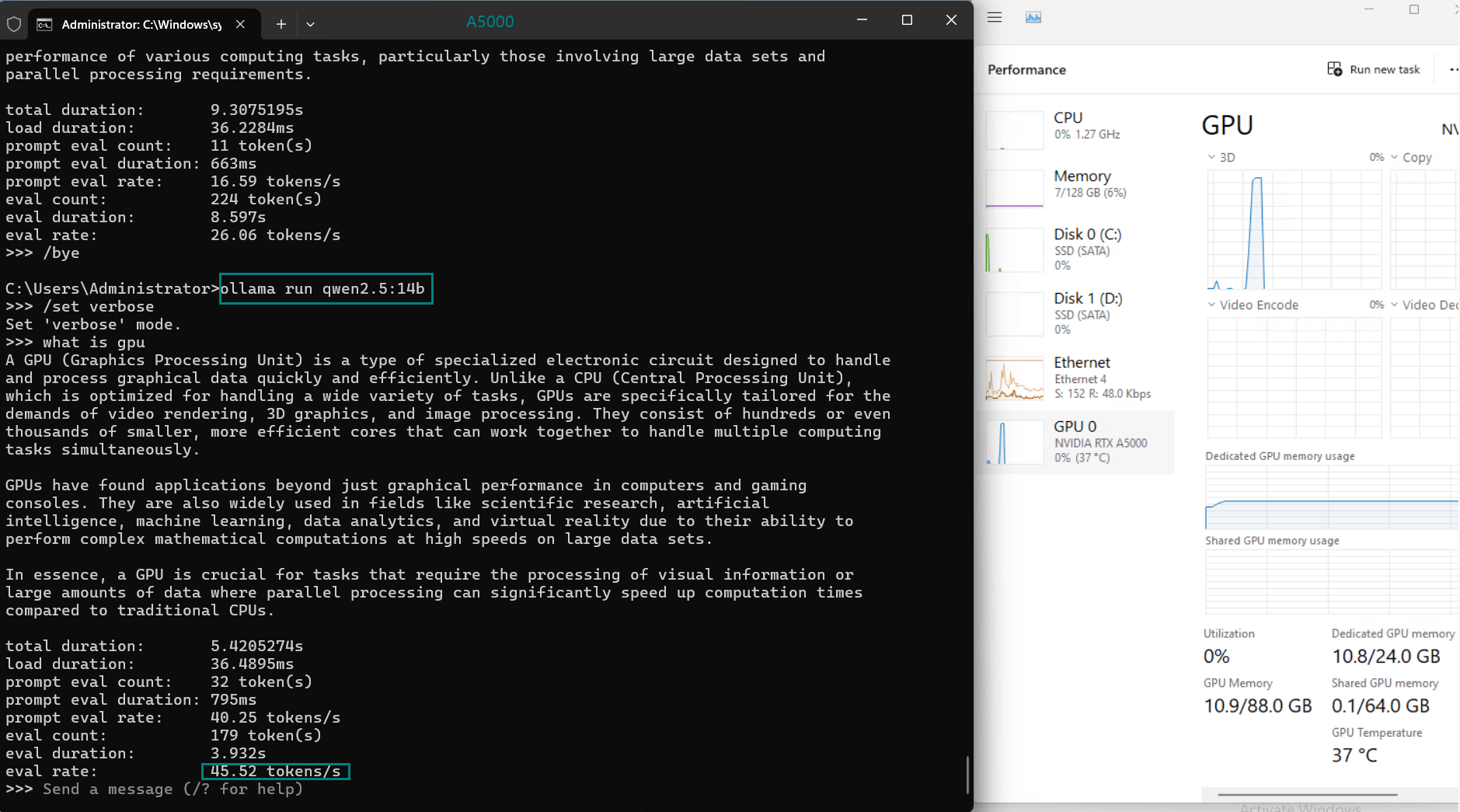
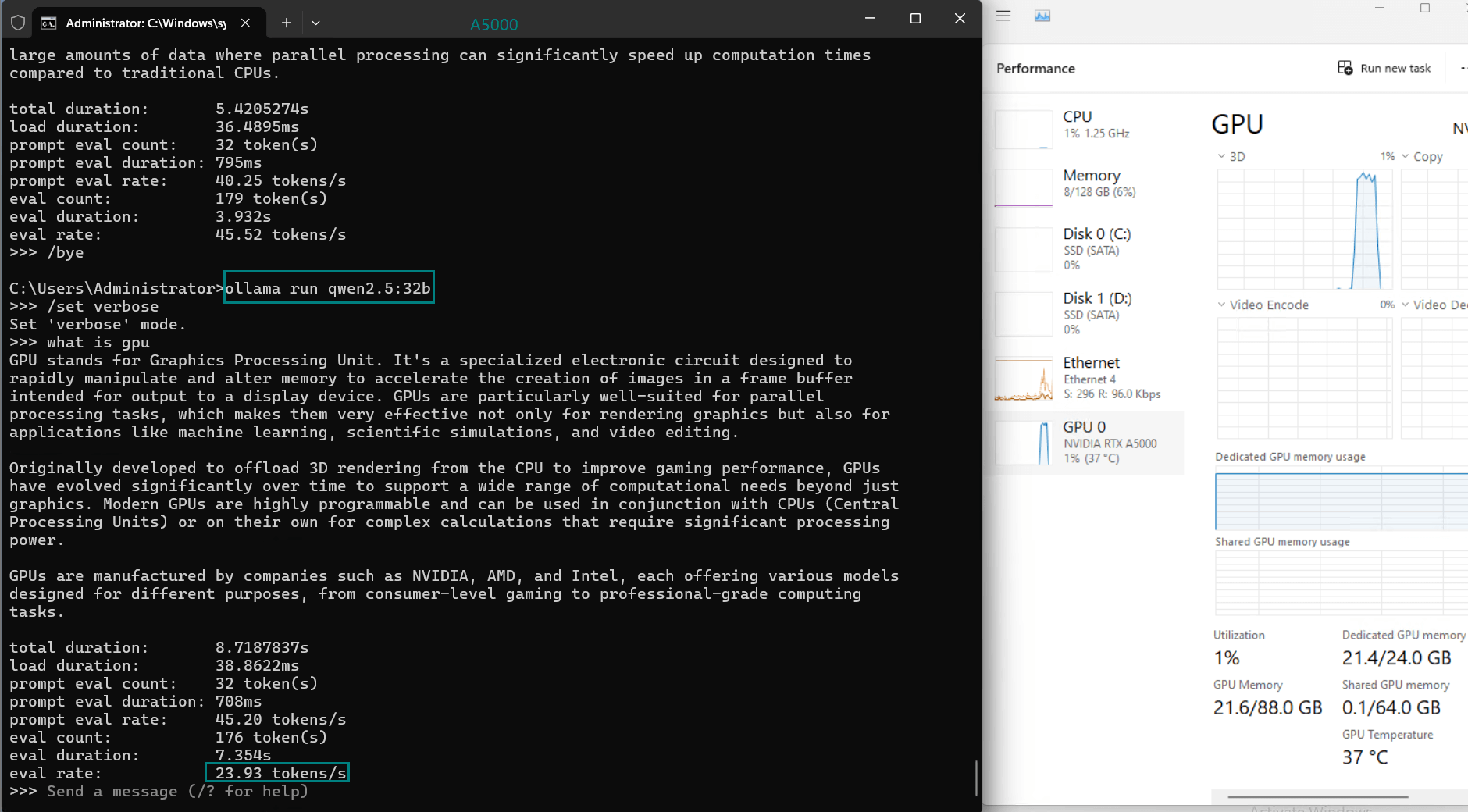
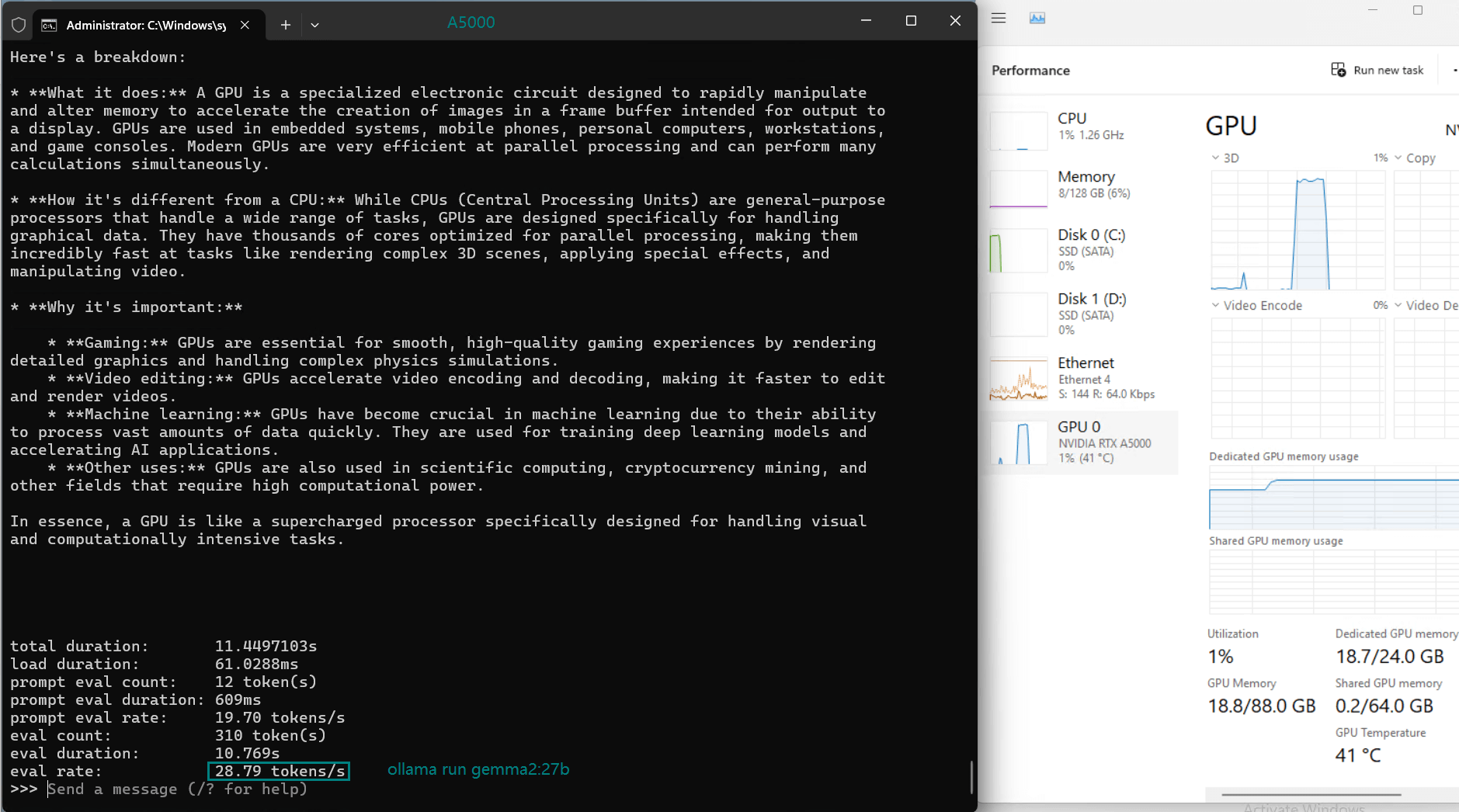
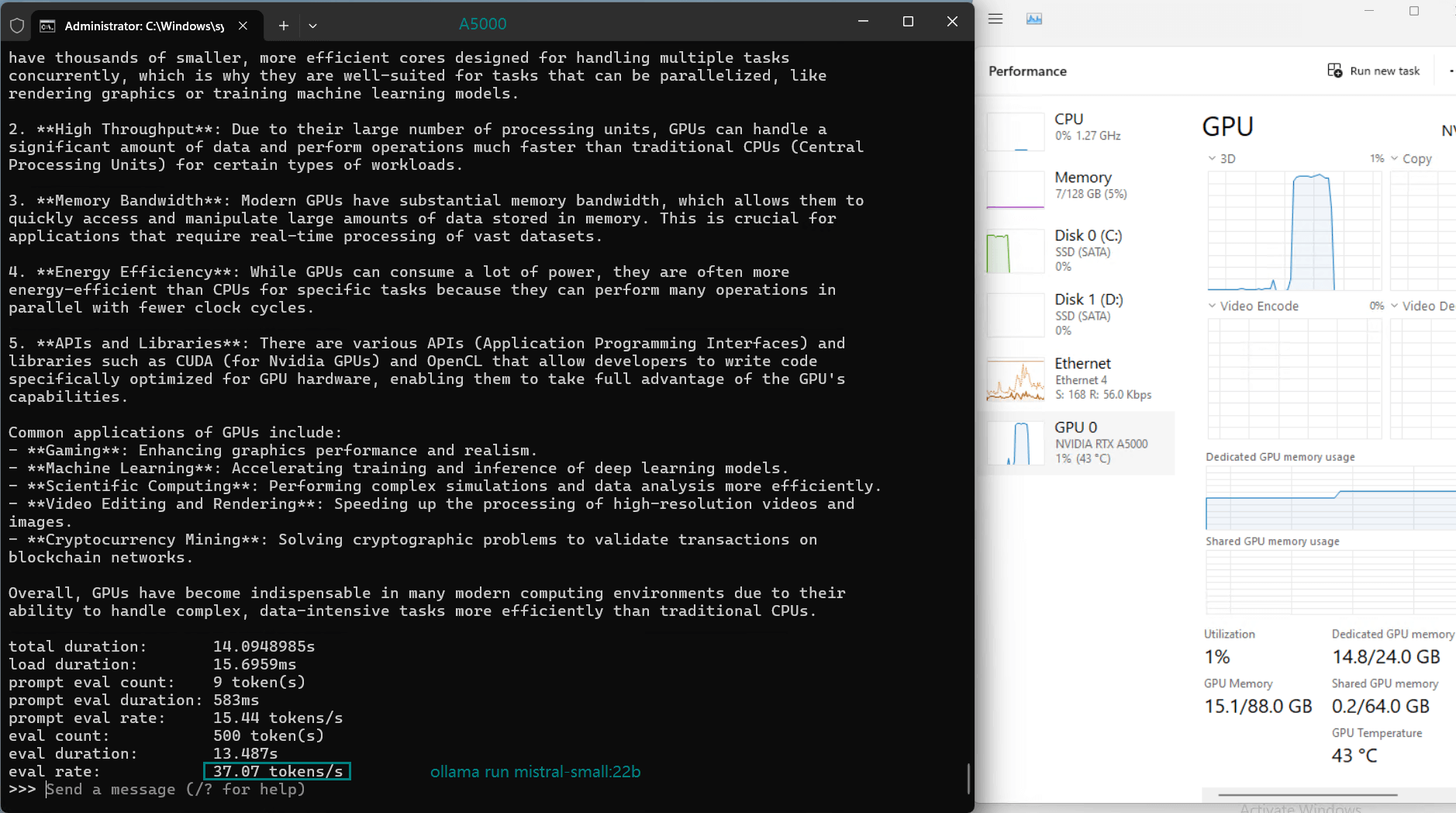
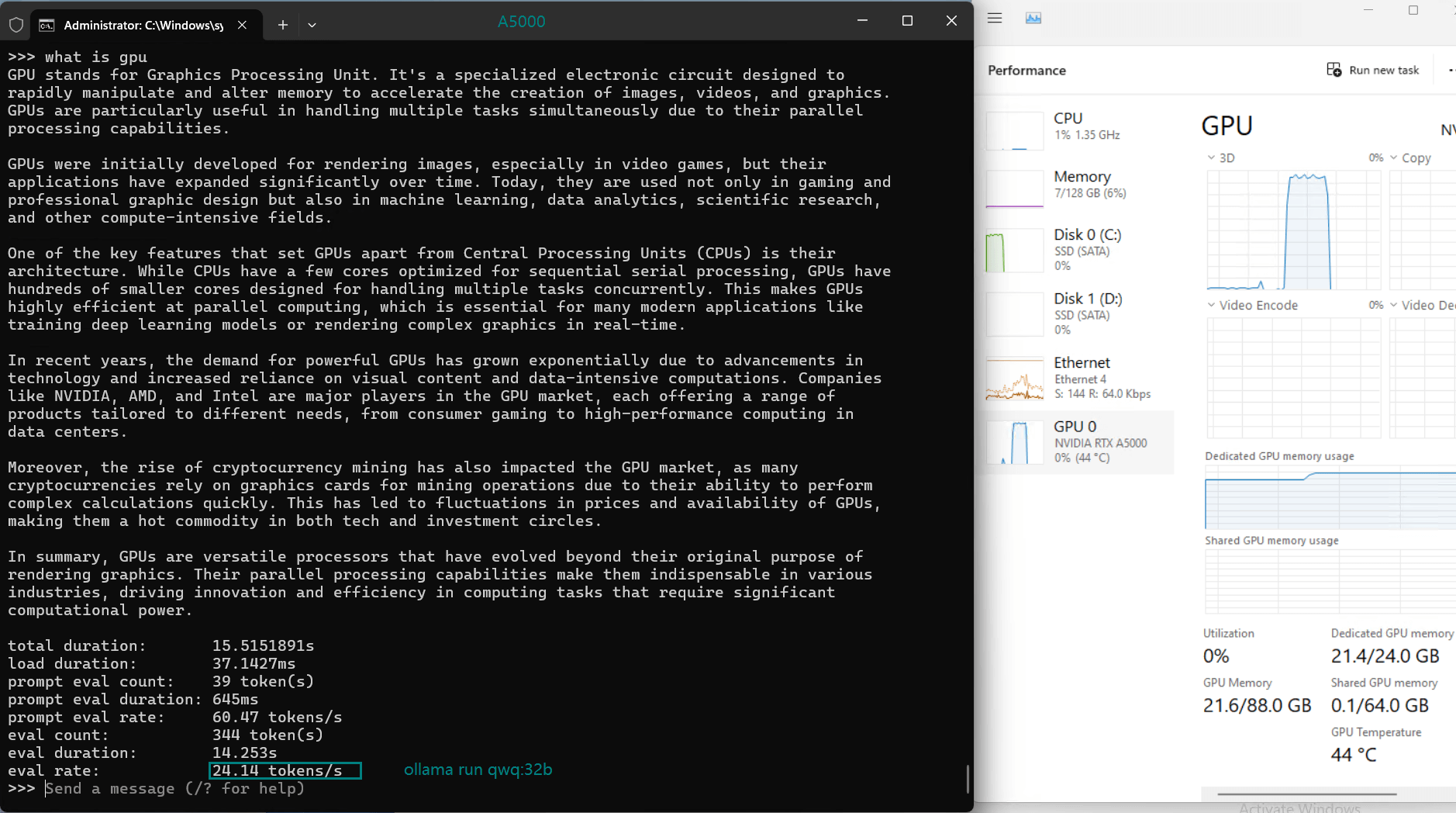
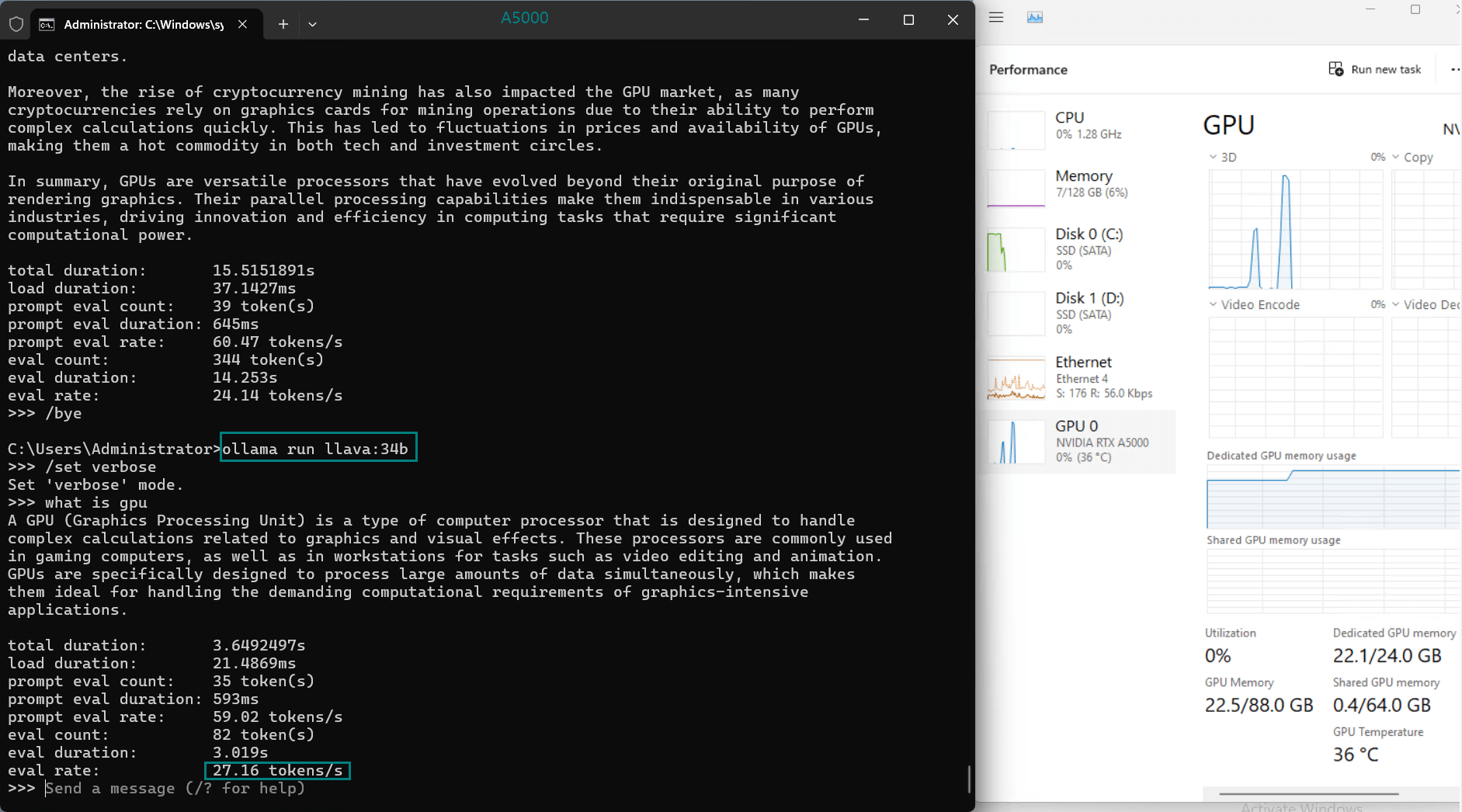
| 模型输出速率(tokens/s) | 45.63 | 24.21 | 60.49 | 26.06 | 45.52 | 23.93 | 28.79 | 37.07 | 24.14 | 27.16 |
一段记录实时A5000 gpu服务器资源消耗数据的视频:
屏幕截图:点击放大并查看
性能分析
1. Token评估速率(tokens/s)
评估率(token/s)是 LLM 托管的一个关键指标,反映了模型处理输入和生成输出的速度:
- Llama2 (13b) 凭借其较小的参数大小和高效的架构,以惊人的 60.49 个 token/s 的速度领先。
- DeepSeek-R1(14b)的表现令人钦佩,达到 45.63 个 token/s,利用其优化的量化来实现快速的处理速度。
- 较大的模型如 Gemma2 (27b) 和 LLaVA (34b) 显示出中等速率,表明它们适合要求更高精度而非速度的任务。
2. GPU 利用率和内存使用情况
- A5000 的 24GB GDDR6 内存为大多数型号提供了充足的空间,其中 DeepSeek-R1 (32b) 在峰值时利用率为 90% VRAM。
- 利用率始终保持在高位(93%-97%),表明所有测试模型均能高效利用 GPU 资源。
3. CPU 和 RAM 效率
- 所有型号的 CPU 率都保持在 3% 的低位,凸显了此服务器上 LLM 托管以 GPU 为中心的特性。
- RAM 使用率徘徊在 6% 左右,确保系统内存仍可用于处理额外的工作负载。
在A5000上托管LLM的优势
1. 多功能性能:A5000能够处理轻量级模型如Llama2,以及重量级模型如Gemma2,且不会出现性能瓶颈。
2. 高效的资源分配:高GPU利用率和低CPU/RAM开销使得该服务器非常适合多任务处理。
3. 面向未来的设计:配备24GB显存,A5000支持更大规模的模型和先进的量化技术。
最佳应用场景
根据基准测试结果,以下是一些推荐的A5000 LLM托管应用场景:
- 实时应用:像Llama2和Qwen2.5这样的模型具备高token评估速率,非常适合用于聊天机器人和对话式AI。
- 研究与开发:托管如DeepSeek-R1和Mistral-Small等多种模型的灵活性,使其适用于与最先进架构的实验和开发。
- 内容生成:像Gemma2和LLaVA这样的较大模型非常适合需要丰富、上下文感知输出的任务。
立即租用A5000专业服务器
NVIDIA Quadro RTX A5000在性能上明显优于较老的GPU。在托管像DeepSeek-R1(14B)这样的LLM时,A5000的评估速率为45.63 tokens/s,几乎是P100的18.99 tokens/s的两倍。其强大的24GB GDDR6显存和19.2 TFLOPS的FP32性能,使其在应对高负载AI任务时,相较于老旧GPU或入门级显卡,成为显而易见的优选。
GPU云服务器 - A4000
¥ 1109.00/月
月付季付年付两年付
立即订购- 配置: 24核32GB, 独立IP
- 存储: 320GB SSD系统盘
- 带宽: 300Mbps 不限流
- 赠送: 每2周一次自动备份
- 系统: Win10/Linux
- 其他: 1个独立IP
- 独显: Nvidia RTX A4000
- 显存: 16GB GDDR6
- CUDA核心: 6144
- 单精度浮点: 19.2 TFLOPS
春季特惠
GPU物理服务器 - A5000
¥ 1249.50/月
立省48% (原价¥2449.00)
月付季付年付两年付
立即订购- CPU: 24核E5-2697v2*2
- 内存: 128GB DDR3
- 系统盘: 240GB SSD
- 数据盘: 2TB SSD
- 系统: Win10/Linux
- 其他: 独立IP,100M-1G带宽
- 独显: Nvidia RTX A5000
- 显存: 24GB GDDR6
- CUDA核心: 8192
- 单精度浮点: 27.8 TFLOPS
春季特惠
GPU物理服务器 - A6000
¥ 2155.44/月
立省44% (原价¥3849.00)
月付季付年付两年付
立即订购- CPU: 36核E5-2697v4*2
- 内存: 256GB DDR4
- 系统盘: 240GB SSD
- 数据盘: 2TB NVMe + 8TB SATA
- 系统: Win10/Linux
- 其他: 独立IP,100M-1G带宽
- 独显: Nvidia RTX A6000
- 显存: 48GB GDDR6
- CUDA核心: 10752
- 单精度浮点: 38.71 TFLOPS
结论
NVIDIA Quadro RTX A5000与Ollama搭配使用,是LLM托管的强大平台。其卓越的GPU性能、高效的资源利用率和灵活性使其成为开发者、研究人员和企业部署AI解决方案的首选。
无论是运行DeepSeek-R1、Llama2还是其他前沿模型,A5000都能提供所需的性能,充分发挥它们的潜力。对于AI爱好者和专业人士而言,这款GPU服务器代表了对机器学习未来的智能投资。
Tags:
NVIDIA A5000, Ollama基准测试, LLM托管, DeepSeek-R1, Llama2, AI GPU服务器, GPU性能测试, AI硬件, 语言模型托管, AI研究工具