



















Nvidia Quadro RTX A6000 基准测试结果:在 GPU 服务器上使用 Ollama 运行 LLM
Nvidia Quadro RTX A6000 是一款性能强大的 GPU,以其在 AI 和机器学习任务中的卓越表现而闻名。本文将深入探讨其在专用 GPU 服务器上运行大型语言模型(LLM)时的表现。基准测试基于 Ollama 环境,涵盖 Llama2、Qwen 等模型的性能评估。
服务器规格
我们的测试环境是一台高性能 GPU 专用服务器,配置如下:
配置详情:
- 价格:$549.00/月
- CPU:双 18 核 E5-2697v4(36 核,72 线程)
- 内存:256GB
- 存储:240GB SSD + 2TB NVMe + 8TB SATA
- 网络:100Mbps-1Gbps
- 操作系统:Windows 10 Pro
显卡详情:
- 显卡:Nvidia Quadro RTX A6000
- 计算能力: 8.6
- 微架构:Ampere
- CUDA 核心: 10,752
- Tensor 核心:336
- GPU 内存: 48GB GDDR6
- FP32 性能: 38.71 TFLOPS
这些强大的配置为使用 Ollama 进行 LLM 基准测试提供了坚实的基础。
基准测试结果:Ollama GPU A6000 性能指标
下表展示了各 LLM 测试的性能指标,包括 CPU、RAM、GPU 利用率及评估速率。测试结果表明,服务器在所有测试中均表现出卓越的稳定性和高效性。
| 模型 | deepseek-r1 | deepseek-r1 | deepseek-r1 | llama2 | llama2 | llama3 | llama3.3 | qwen | qwen | qwen2.5 | qwen2.5 | gemma2 | llava | qwq | phi4 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 参数 | 14b | 32b | 70b | 13b | 70b | 70b | 70b | 32b | 72b | 14b | 32b | 27b | 34b | 32b | 14b |
| 文件大小(GB) | 9GB | 20GB | 43GB | 7.4GB | 39GB | 40GB | 43GB | 18GB | 41GB | 9GB | 20GB | 16GB | 19GB | 20GB | 9.1GB |
| 量化程度 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| 运行平台 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 |
| 模型下载速度(mb/s) | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 |
| CPU 利用率 | 3% | 3% | 3% | 3% | 5% | 3% | 3% | 3% | 3% | 3% | 3% | 3% | 3% | 3% | |
| RAM 利用率 | 4% | 4% | 4% | 3% | 3% | 3% | 3% | 4% | 3% | 3% | 4% | 3% | 4% | 4% | 4% |
| GPU vRAM | 78% | 68% | 90% | 30% | 85% | 88% | 91% | 42% | 91% | 22% | 67% | 40% | 85% | 91% | 70% |
| GPU 利用率 | 86% | 92% | 96% | 87% | 96% | 94% | 94% | 89% | 94% | 83% | 89% | 84% | 68% | 89% | 83% |
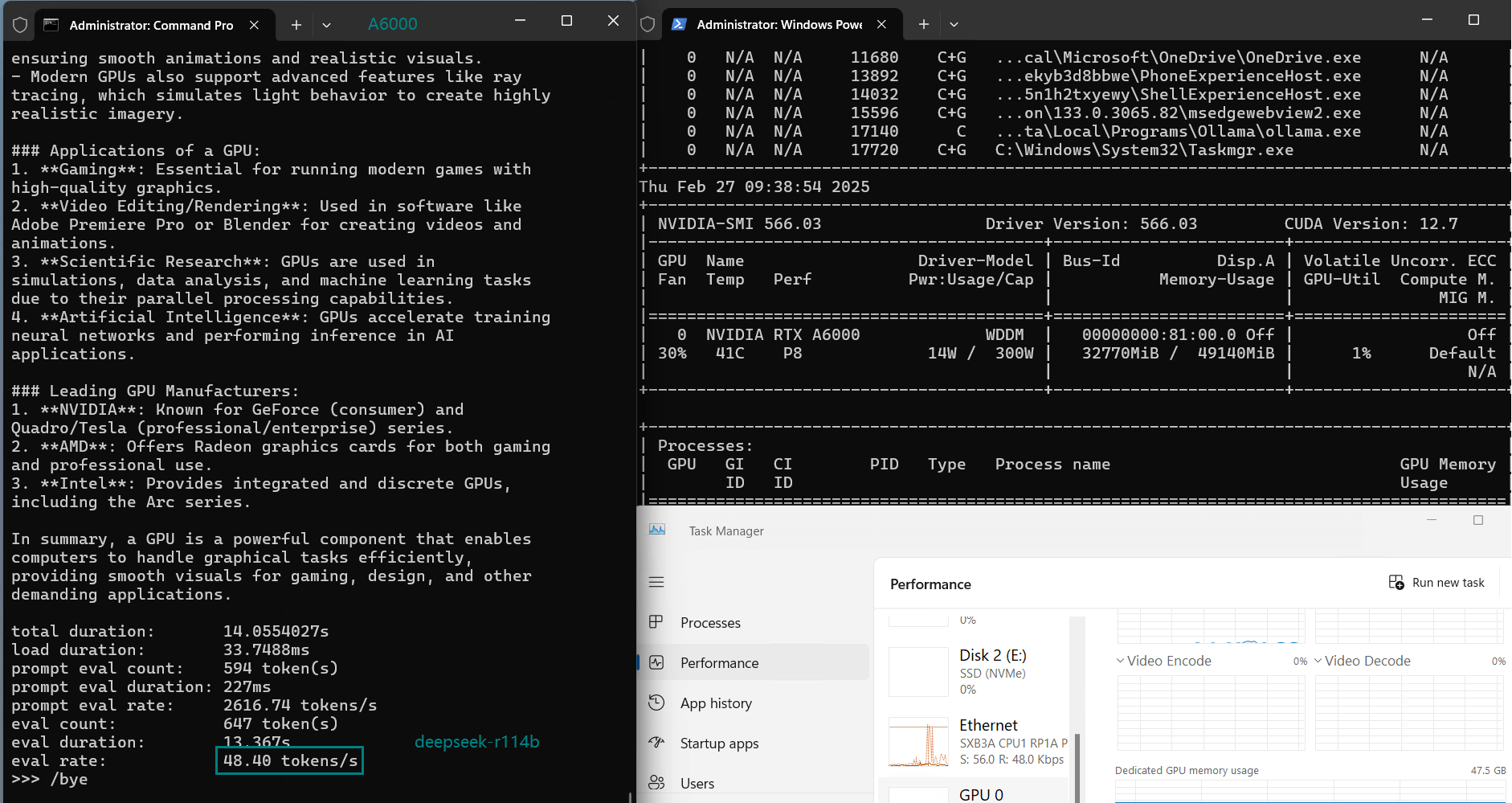
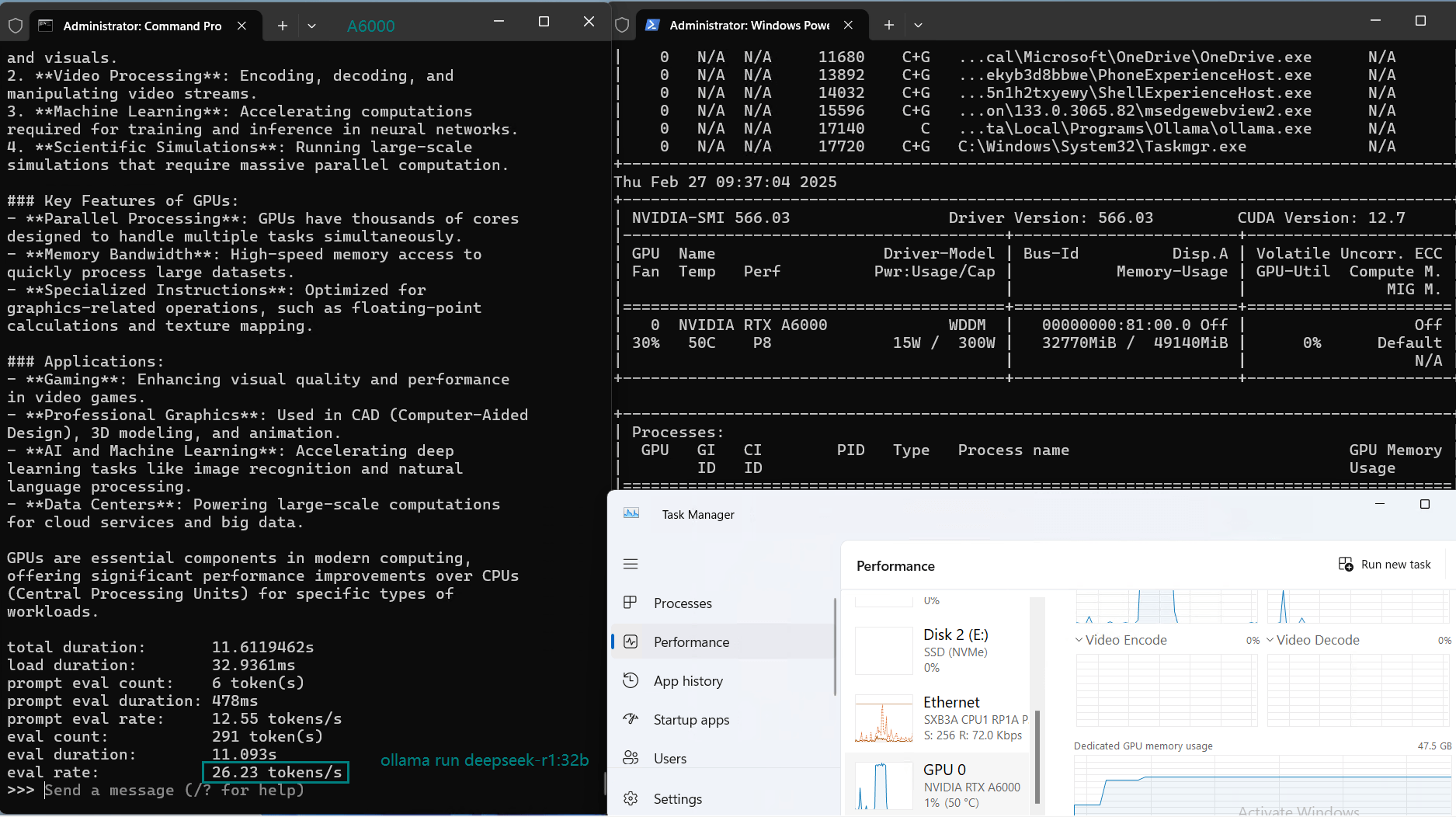
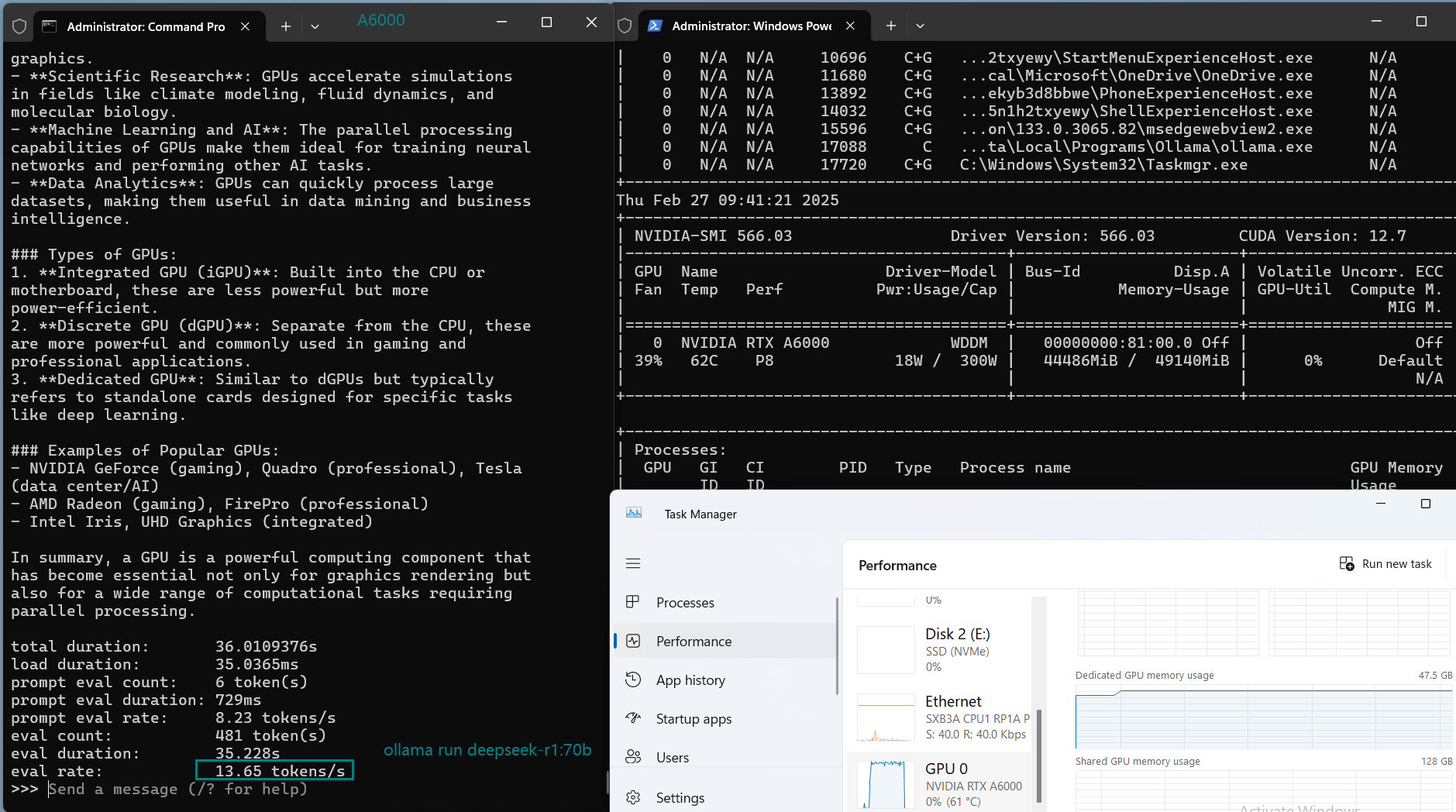
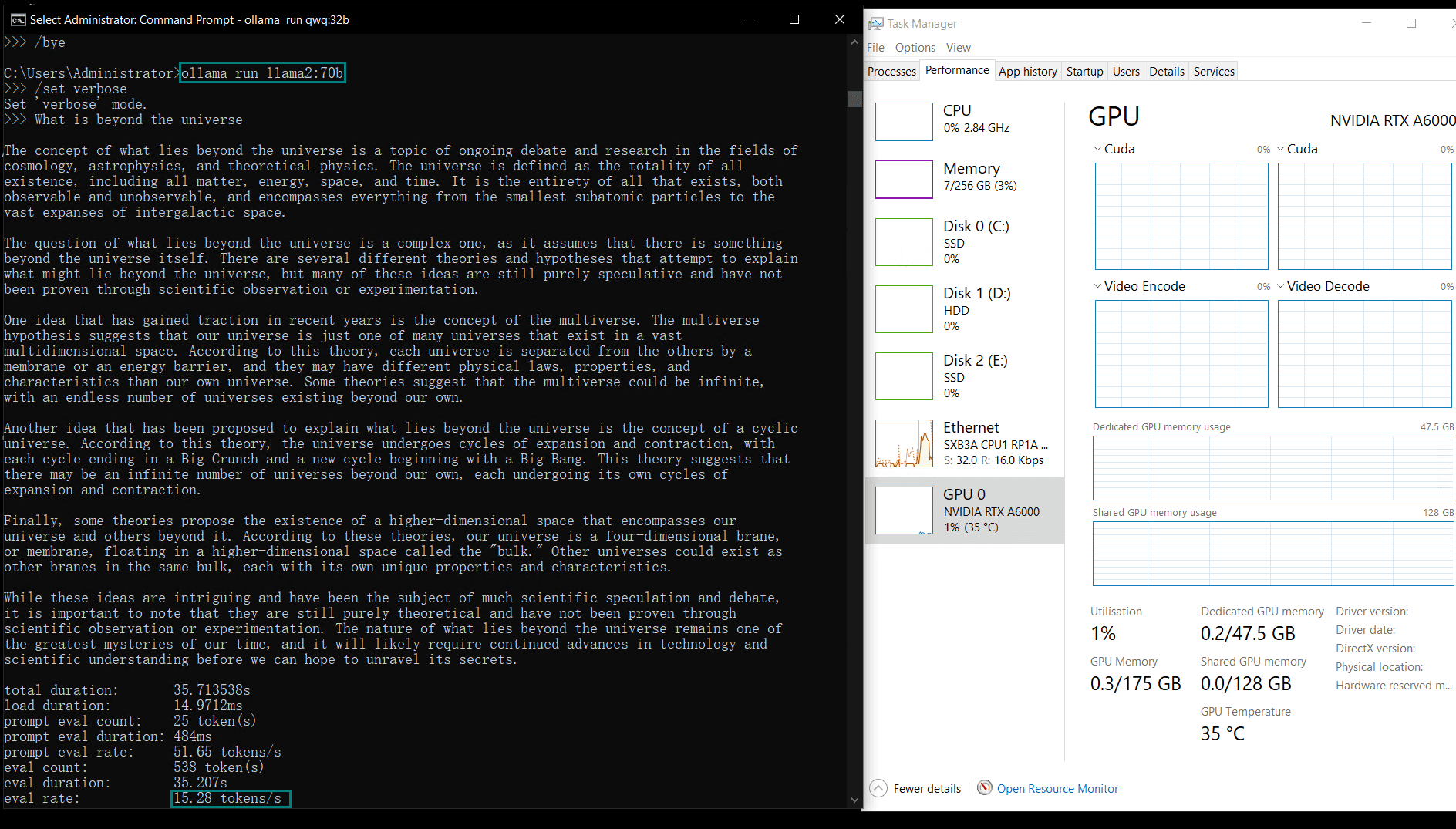
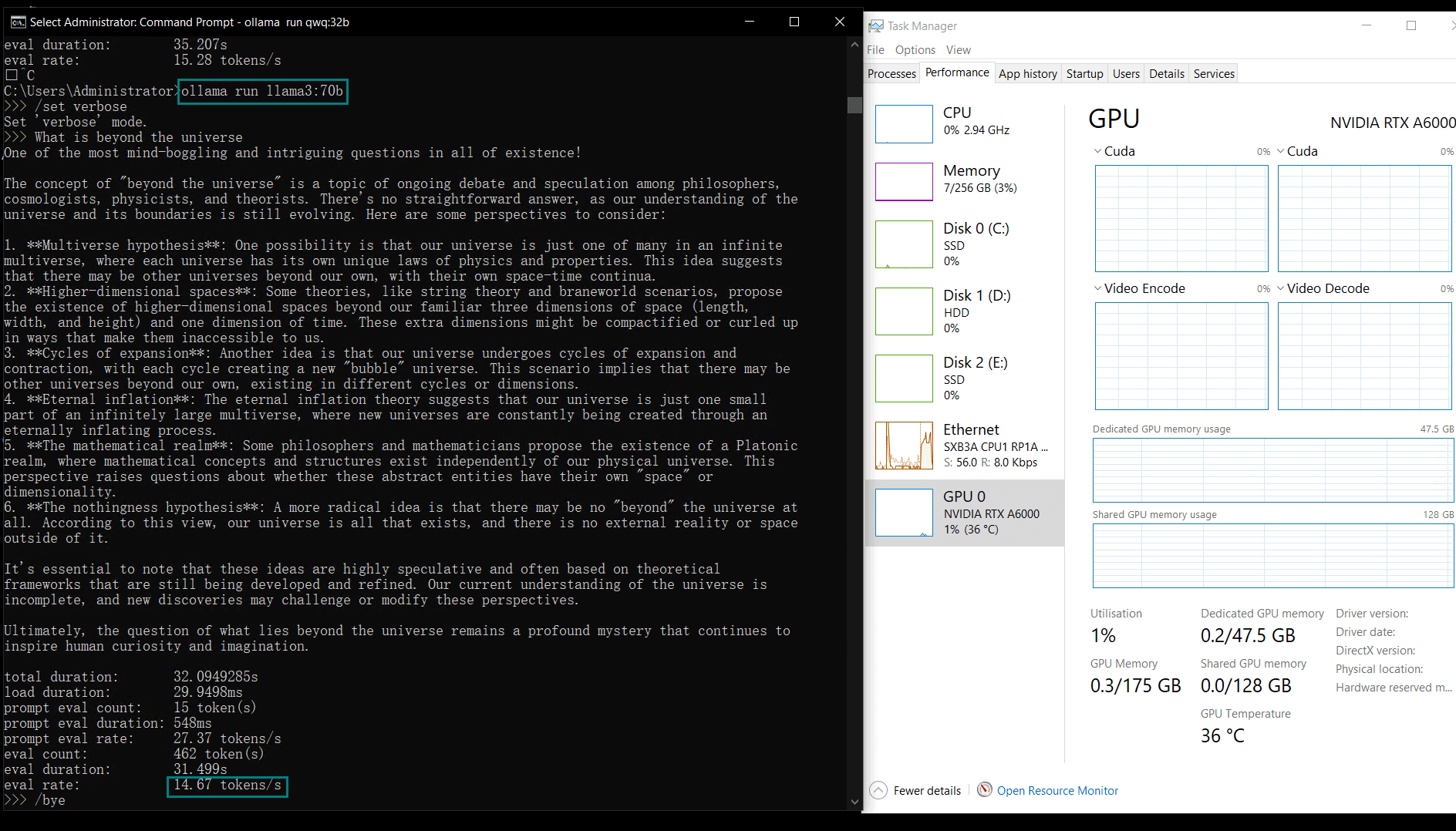
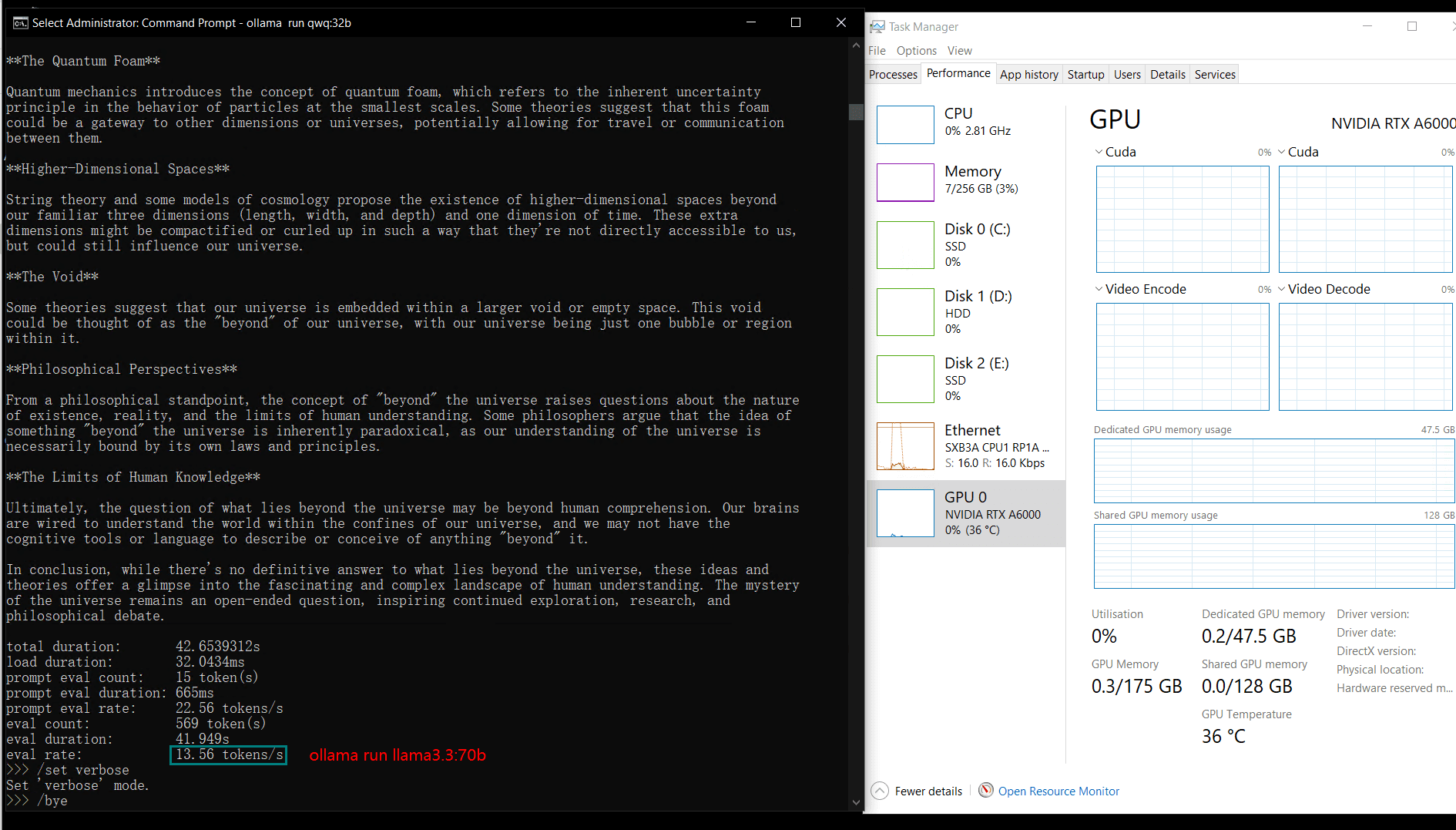
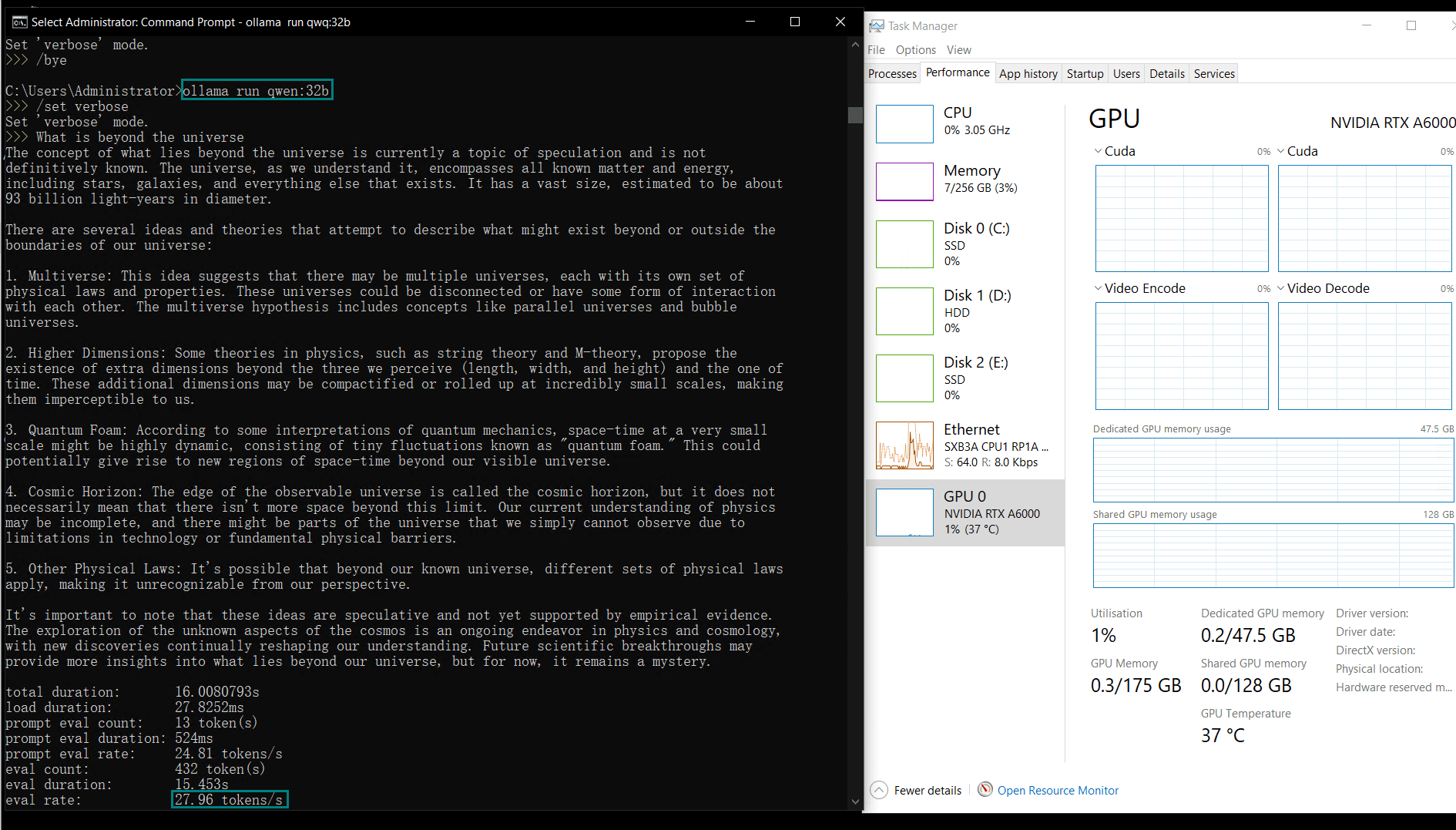
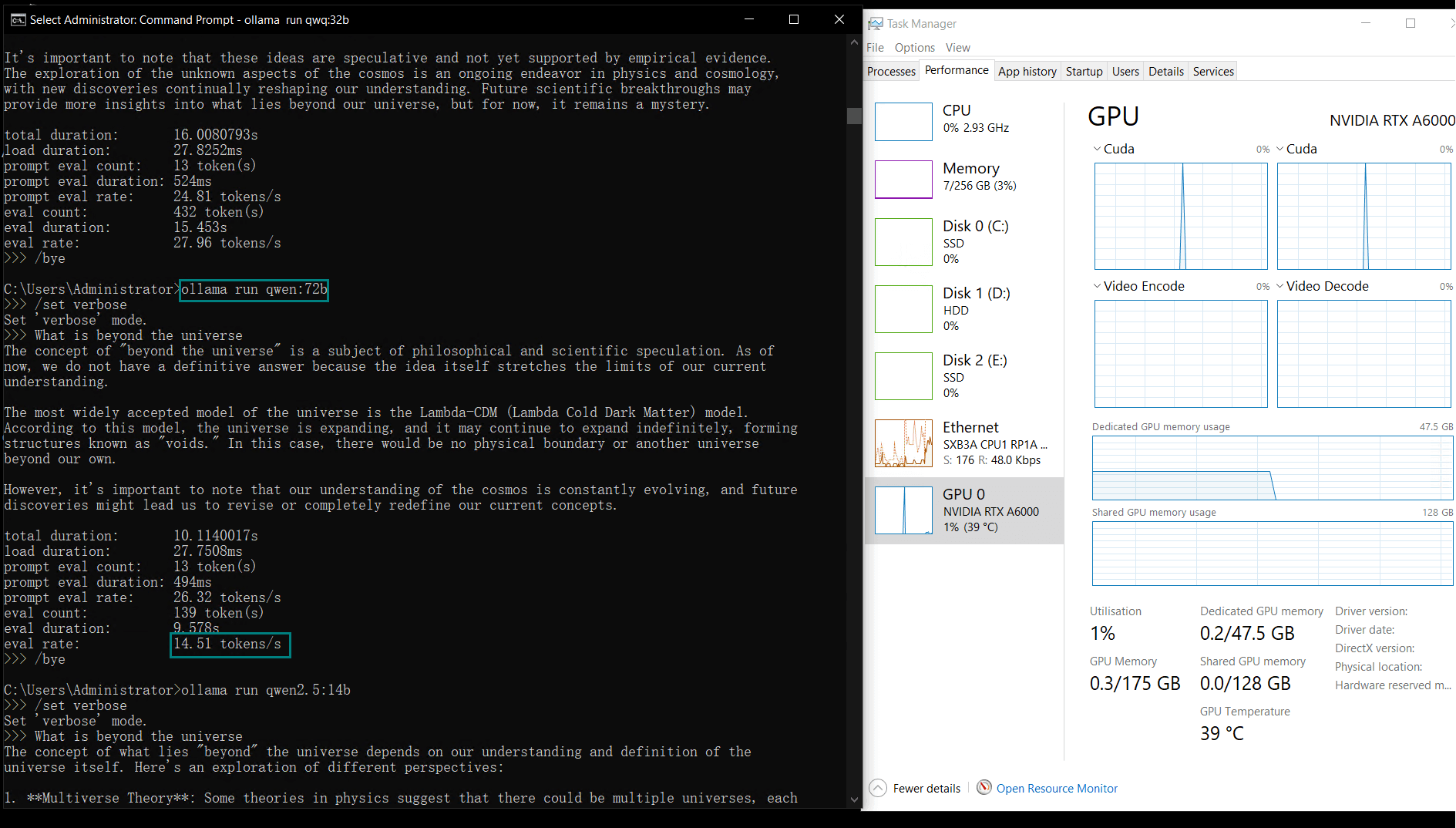
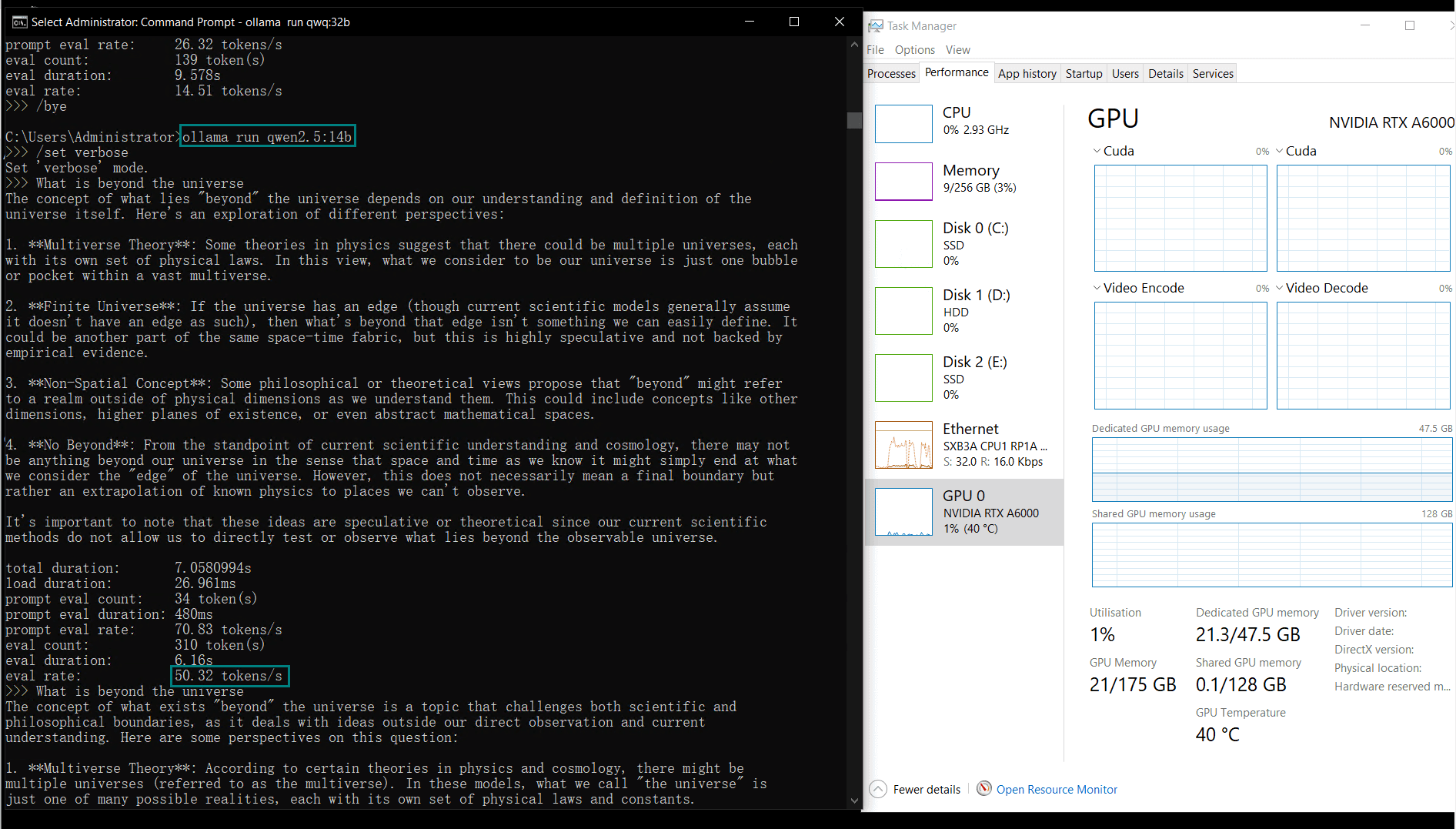
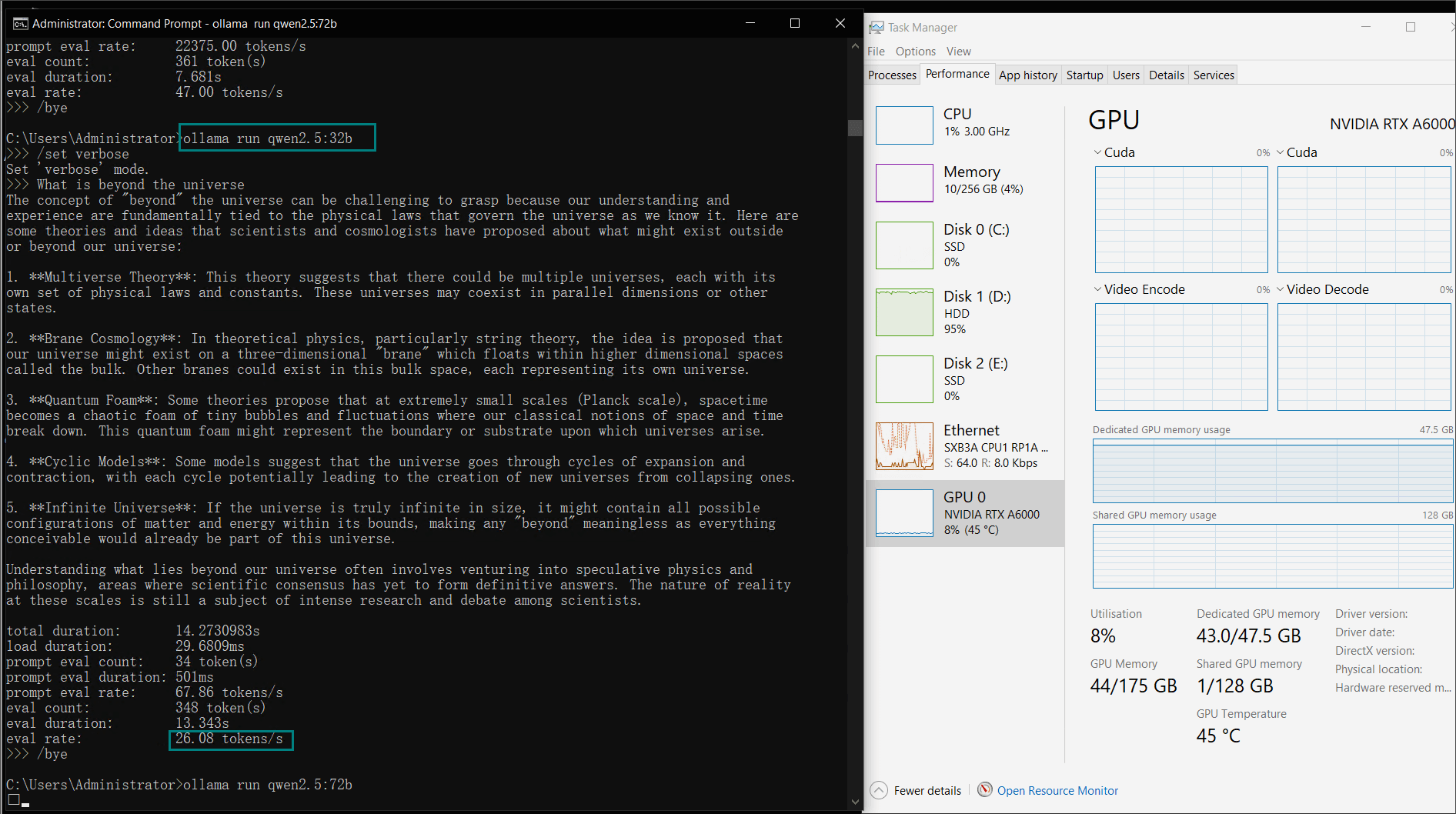
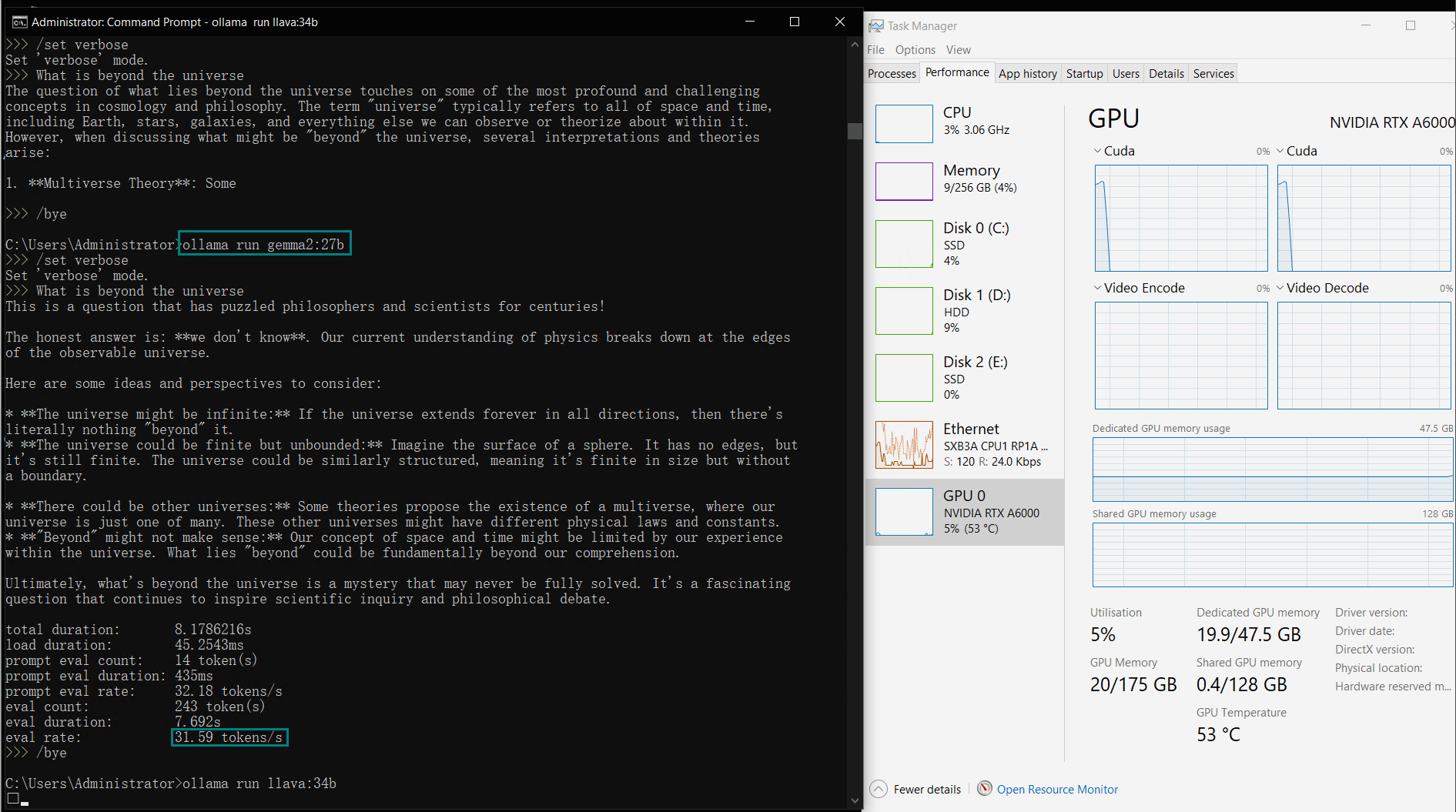
| 模型输出速率(tokens/s) | 48.40 | 26.23 | 13.65 | 63.63 | 15.28 | 14.67 | 13.56 | 27.96 | 14.51 | 50.32 | 26.08 | 31.59 | 28.67 | 25.57 | 52.62 |
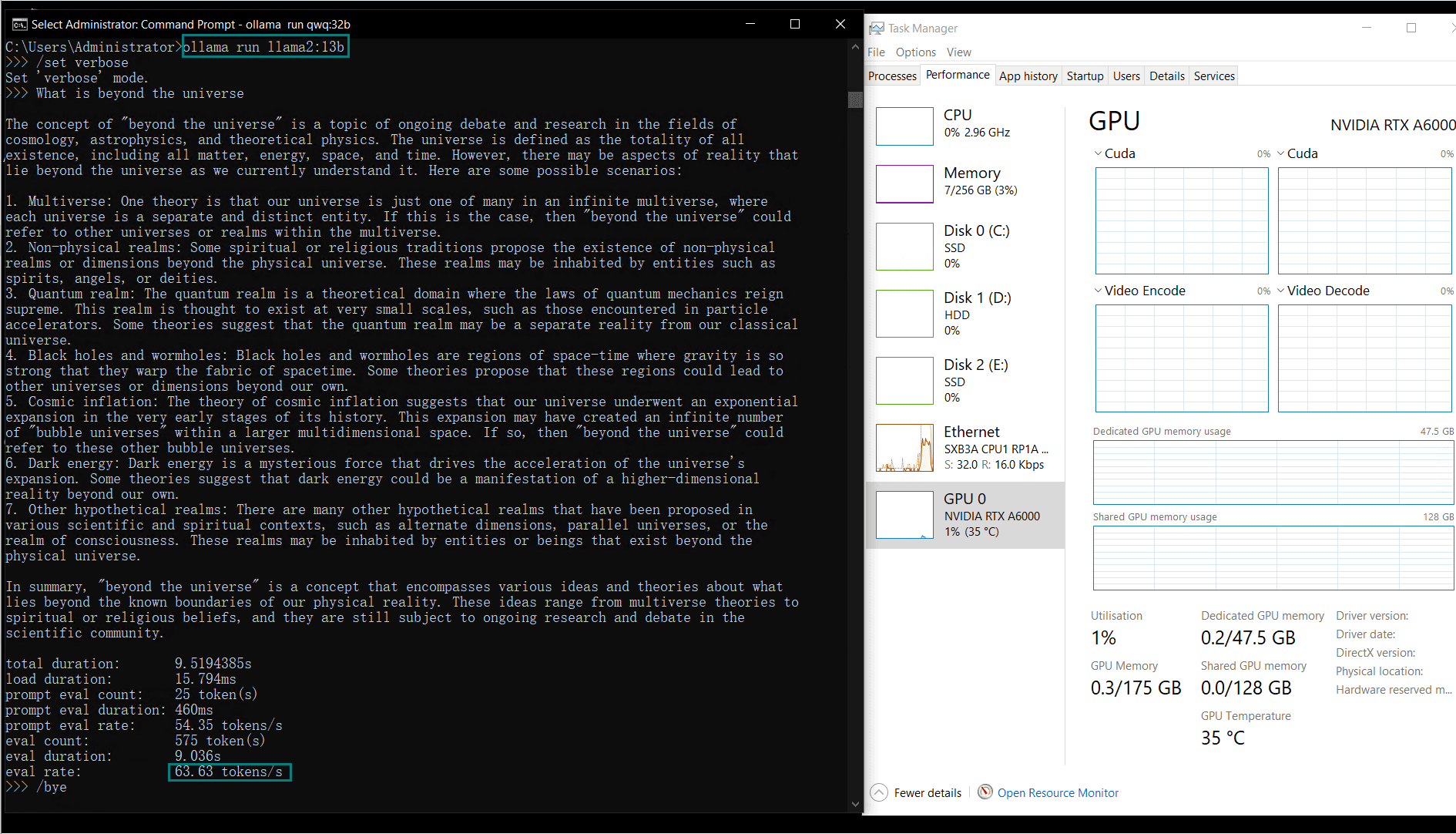
视频记录实时GPU服务器资源消耗数据:
实时截屏:基准测试结果数据
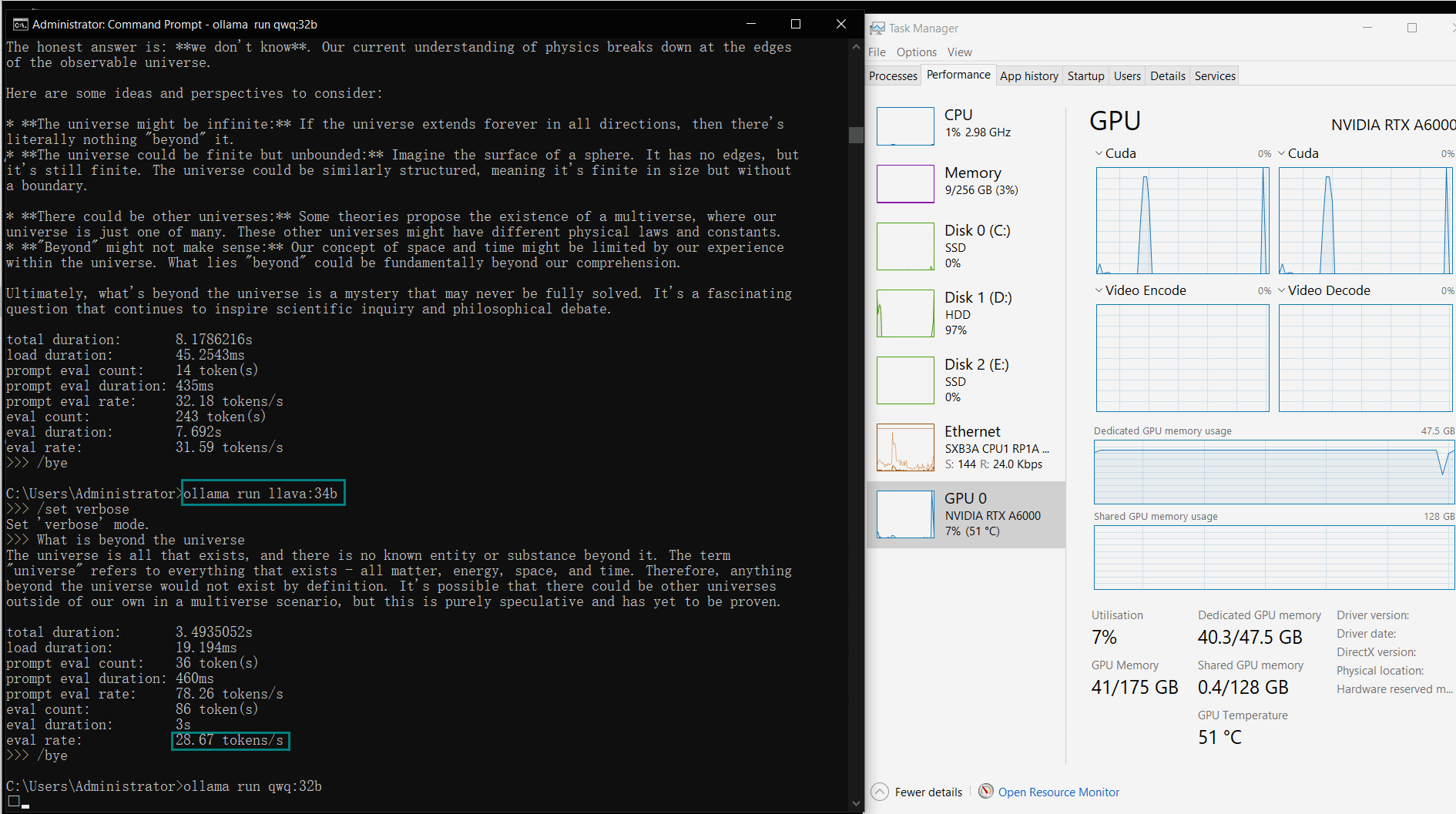
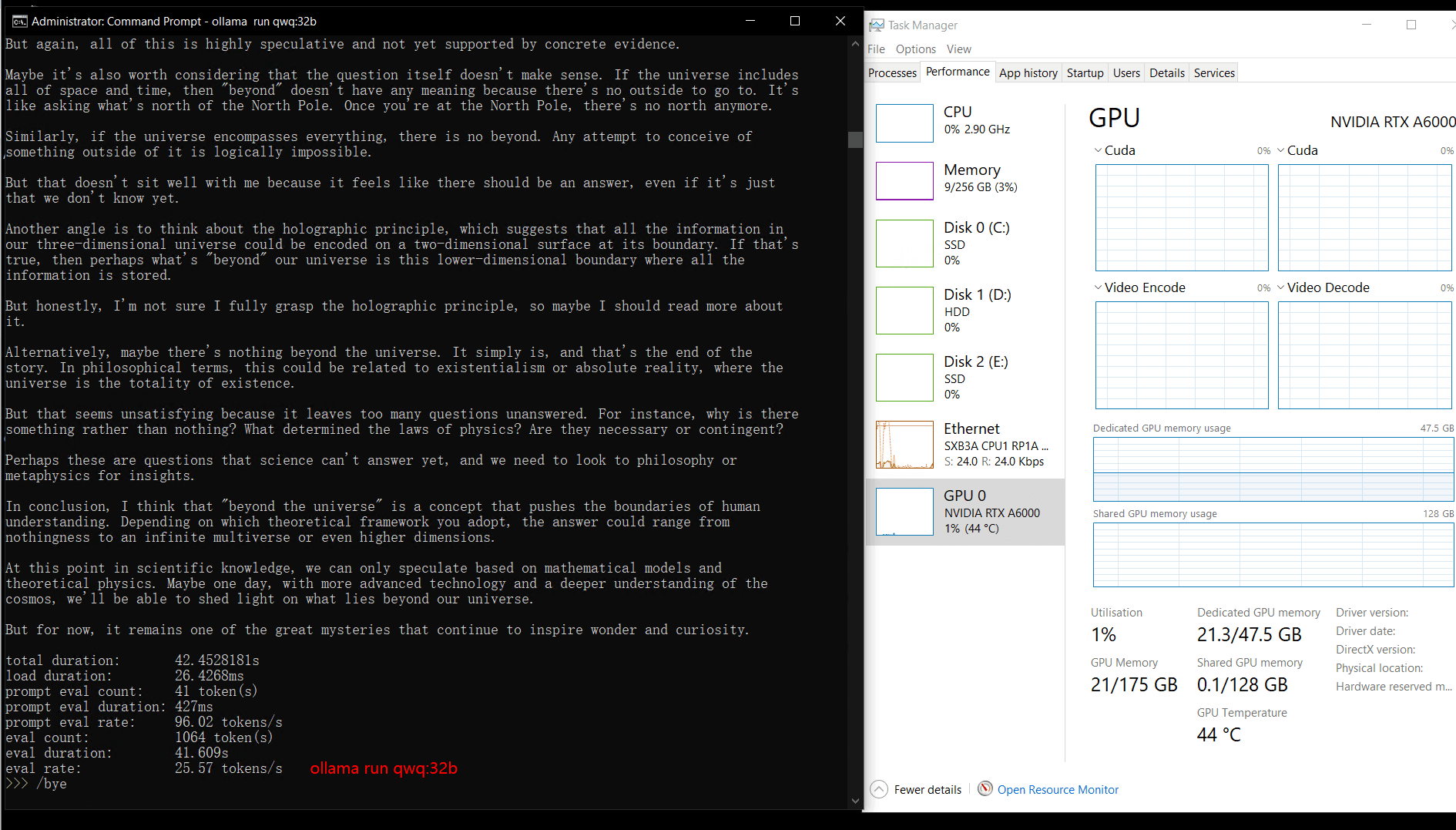
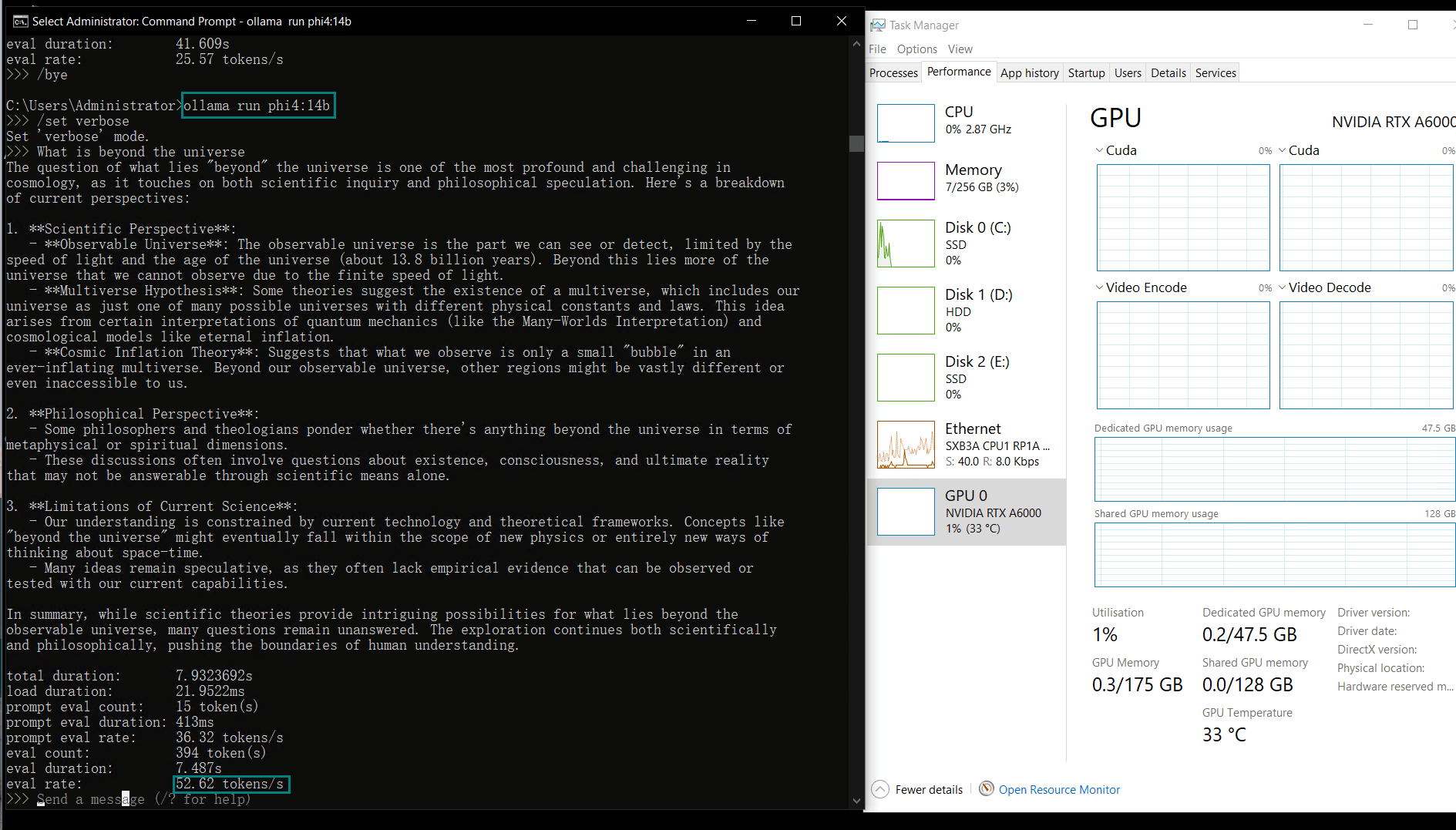
性能分析
1. LLM兼容性
A6000能够无缝处理各种LLM,包括大型模型如Llama2 70B、Qwen 72B,以及紧凑型模型如Qwen2.5 14B。
2. 评估速率
较小的模型(例如Llama2 13B、Phi4 14B)由于计算需求较低,达到了更高的token评估速率。较大模型则在保持稳定性的同时,评估速率略有下降。
3. GPU利用率
A6000始终保持高GPU利用率,展现了其应对高负载工作负载的能力。
4. vRAM使用情况
参数较大的模型,如Llama2 70B,最大可利用48GB GDDR6显存的91%,展示了A6000在处理内存密集型任务方面的能力。
| 指标 | 各模型的数值 |
|---|---|
| 下载速度 | 所有模型为11 MB/s,当订购1gbps带宽附加包时,速度为118 MB/s。 |
| CPU利用率 | 保持在3% |
| RAM利用率 | 保持在3% |
| GPU vRAM利用率 | 22%-91%。模型越大,利用率越高。 |
| GPU利用率 | 80%以上,保持高利用率。 |
| 评估速度 | 13.56 - 63.63 tokens/s。模型越大,推理速度越慢。 |
立即订购A6000 专业服务器
A6000是一款专业级显卡,在同价位的GPU卡中表现出色,尤其适用于高性能计算、AI推理和图形设计等场景,是70b(43GB)大语言模型的入门选择。
春季特惠
GPU云服务器 - A4000
¥ 692.45/月
立省45% (原价¥1259.00)
月付季付年付两年付
立即订购- 配置: 24核32GB, 独立IP
- 存储: 320GB SSD系统盘
- 带宽: 300Mbps 不限流
- 赠送: 每2周一次自动备份
- 系统: Win10/Linux
- 其他: 1个独立IP
- 独显: Nvidia RTX A4000
- 显存: 16GB GDDR6
- CUDA核心: 6144
- 单精度浮点: 19.2 TFLOPS
春季特惠
GPU物理服务器 - A5000
¥ 1249.50/月
立省48% (原价¥2499.00)
月付季付年付两年付
立即订购- CPU: 24核E5-2697v2*2
- 内存: 128GB DDR3
- 系统盘: 240GB SSD
- 数据盘: 2TB SSD
- 系统: Win10/Linux
- 其他: 独立IP,100M-1G带宽
- 独显: Nvidia RTX A5000
- 显存: 24GB GDDR6
- CUDA核心: 8192
- 单精度浮点: 27.8 TFLOPS
GPU物理服务器 - A40
¥ 3079.00/月
月付季付年付两年付
立即订购- CPU: 36核E5-2697v4*2
- 内存: 256GB DDR4
- 系统盘: 240GB SSD
- 数据盘: 2TB NVMe + 8TB SATA
- 系统: Win10/Linux
- 其他: 独立IP,100M-1G带宽
- 独显: Nvidia A40
- 显存: 48GB GDDR6
- CUDA核心: 10752
- 单精度浮点: 37.48 TFLOPS
春季特惠
GPU物理服务器 - A6000
¥ 2155.44/月
立省44% (原价¥3849.00)
月付季付年付两年付
立即订购- CPU: 36核E5-2697v4*2
- 内存: 256GB DDR4
- 系统盘: 240GB SSD
- 数据盘: 2TB NVMe + 8TB SATA
- 系统: Win10/Linux
- 其他: 独立IP,100M-1G带宽
- 独显: Nvidia RTX A6000
- 显存: 48GB GDDR6
- CUDA核心: 10752
- 单精度浮点: 38.71 TFLOPS
总结与建议
Nvidia Quadro RTX A6000,在专用GPU服务器上运行,通过Ollama执行LLM时表现出色。其强大的性能指标、计算资源的高效利用以及与多种模型的兼容性,使其成为AI开发者的顶级选择。
如果您正在寻找高性能的A6000托管或用于LLM基准测试的环境,这种配置在研究和生产应用场景中都能提供卓越的价值。
标签:
Nvidia Quadro RTX A6000, A6000基准测试, LLM基准测试, Ollama基准测试, A6000 GPU性能, 在A6000上运行LLM, Nvidia A6000托管, Ollama GPU测试, AI GPU基准测试, 大型语言模型的GPU, A6000与RTX 4090对比, AI GPU托管